Patterns in disaster frequency, location clustering, response performance, and recovery outcomes over time and across regions.
Links to contributors: Trenton Harris, Gray Huddleston, Nathan Reese.
For our project, we used a global natural disasters data set covering 2018 to 2024. The data set includes records of disasters occurring worldwide and provides both geographic and impact/response-related variables. Key fields include: Date of disaster occurrence, Country affected, Disaster type (e.g., flood, earthquake), Severity index (numeric measure of disaster severity), Casualties (people affected or killed), Economic loss (USD), Response time (hours), Aid amount (USD), Response efficiency score (0–100), Recovery days, and Geographic latitude (and associated location fields such as longitude) This data set allowed our team to explore patterns in disaster frequency, location clustering, response performance, and recovery outcomes over time and across regions.
We then took this data to answer 4 questions with visualization aids:
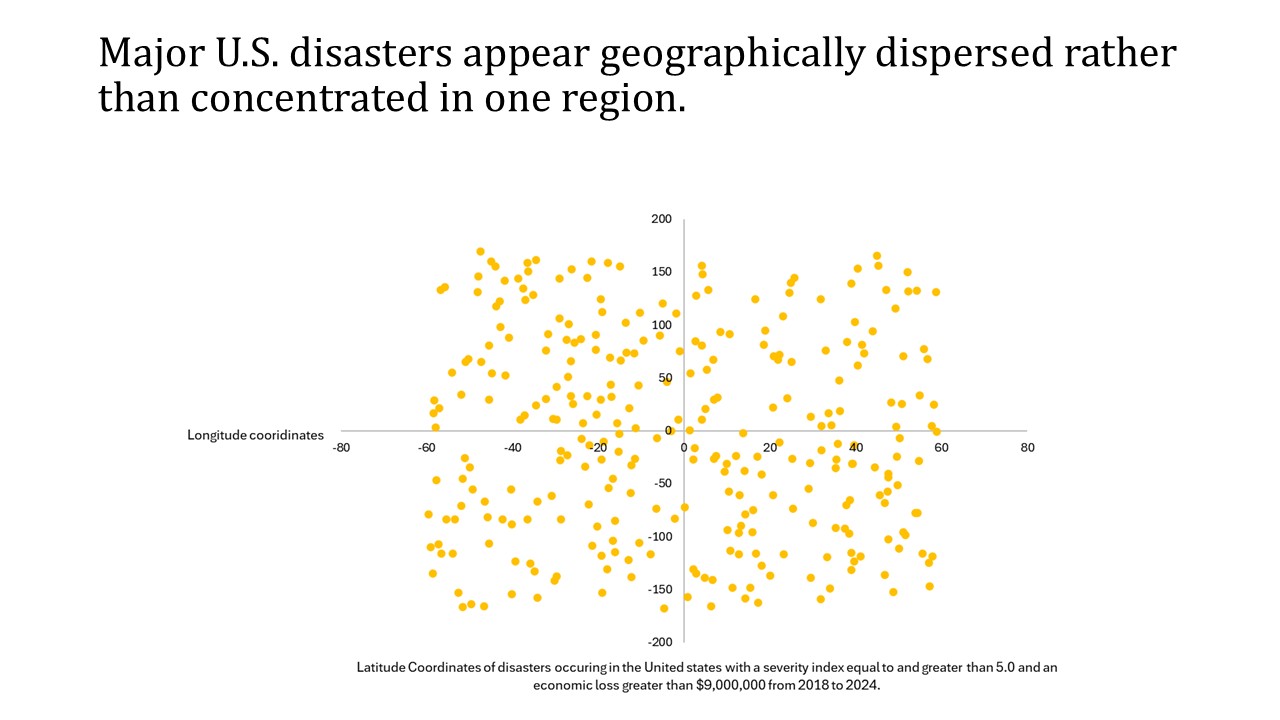
Is there a geographical pattern among disasters occurring in the United States?
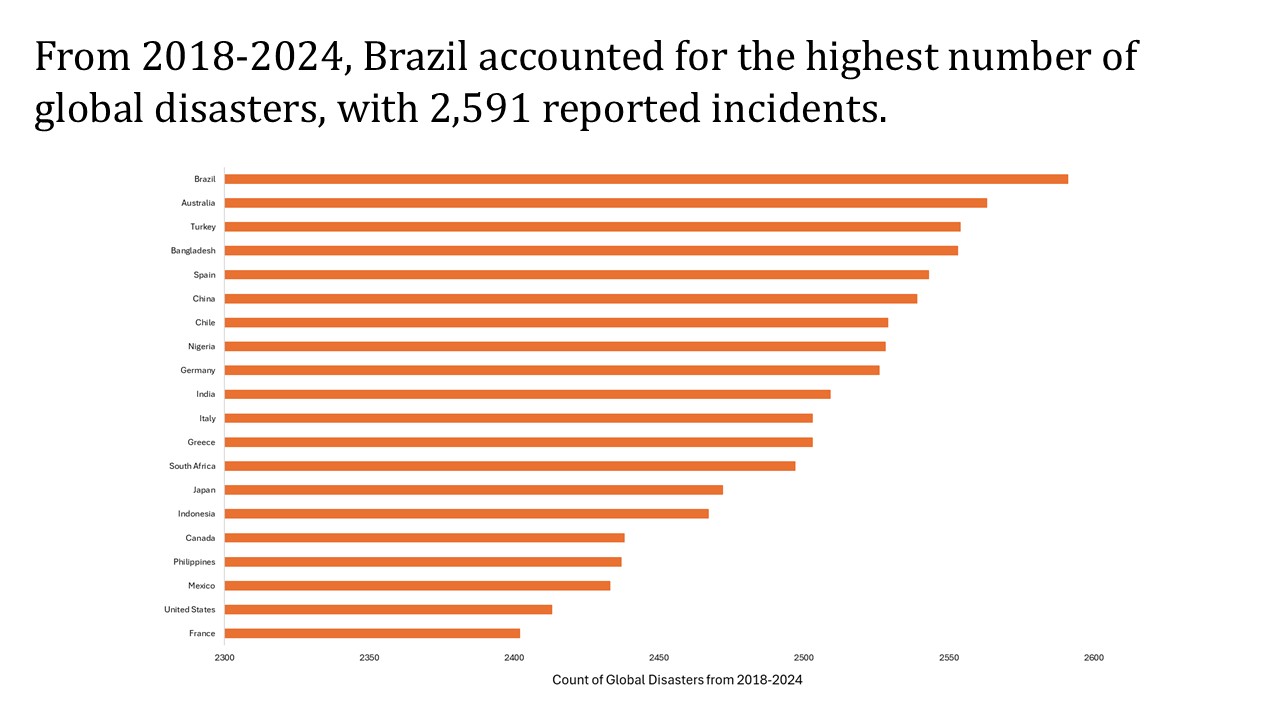
Which country experienced the most natural disasters?
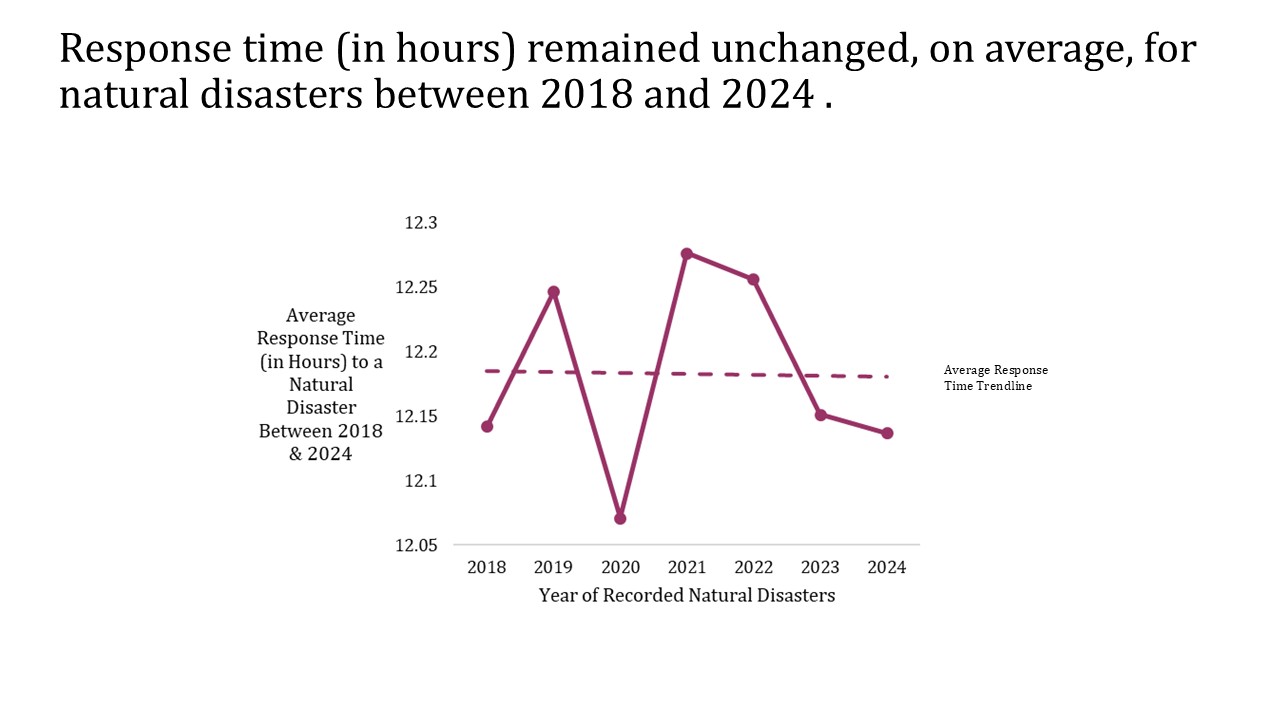
Has the average response time changed over the years?
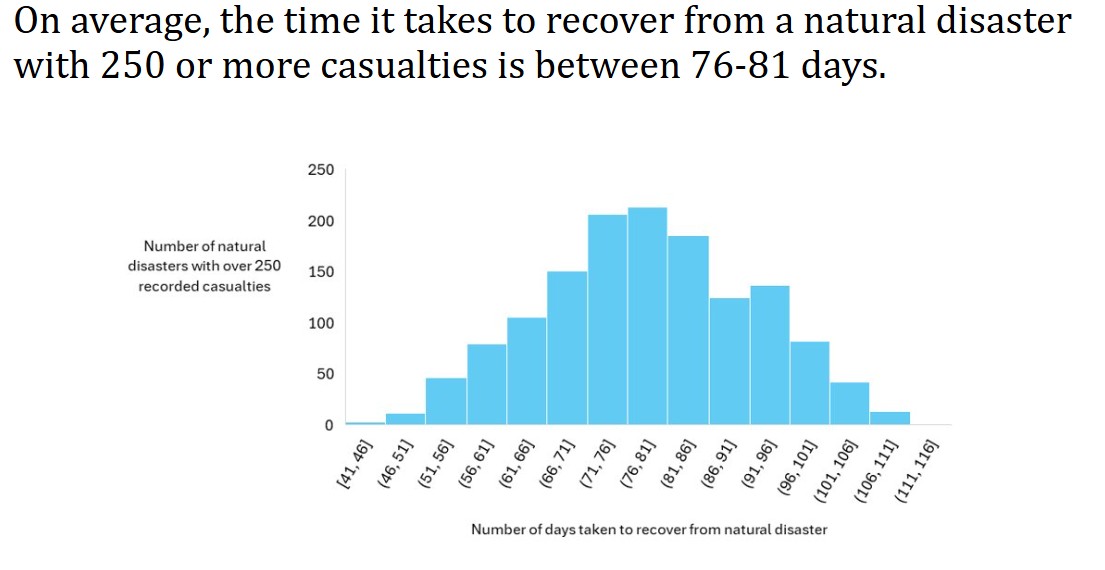
What is the average recovery days for natural disasters with 250 or more casualties?